Sarah: Hallucination Detection for Large Vision Language Models with Semantic Information Locator and Purifier in Uncertainty Quantification Method
Published in IMAVIS, 2026
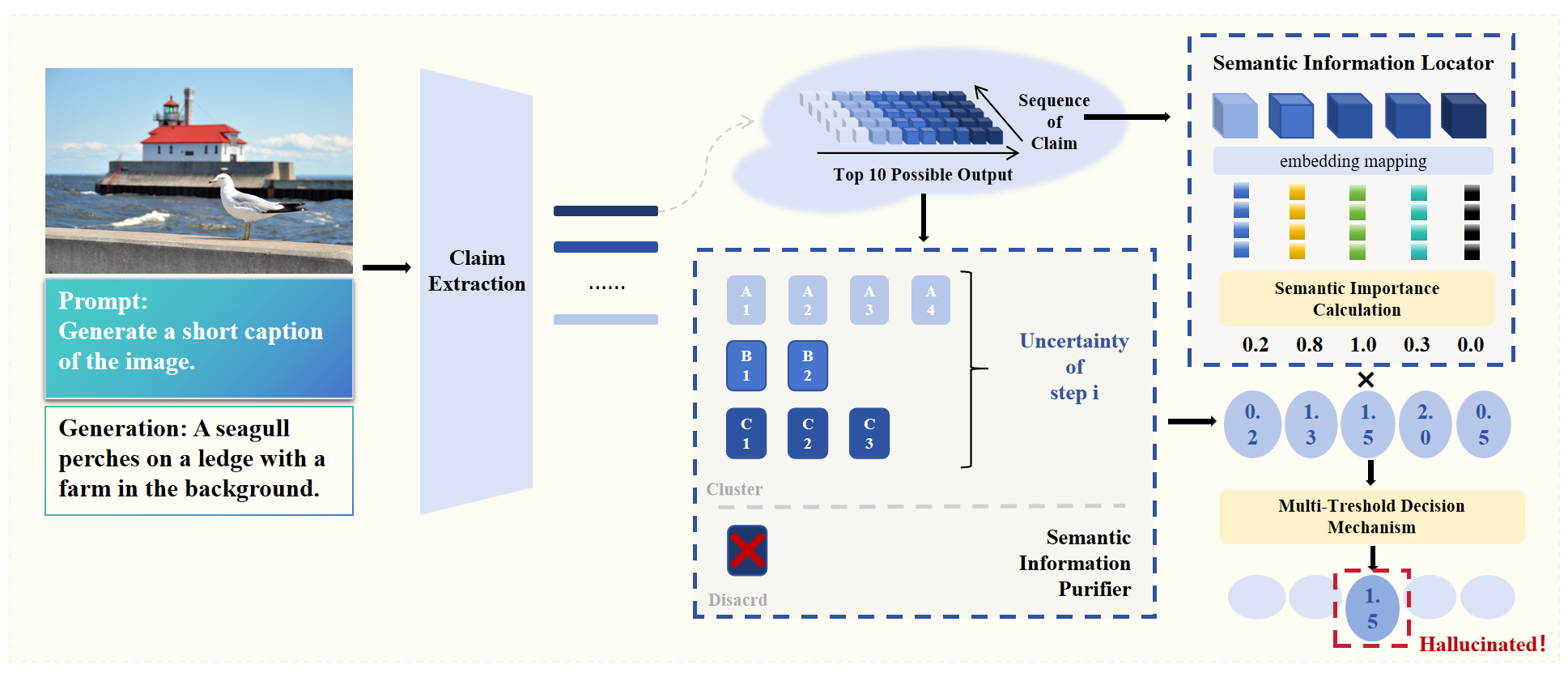
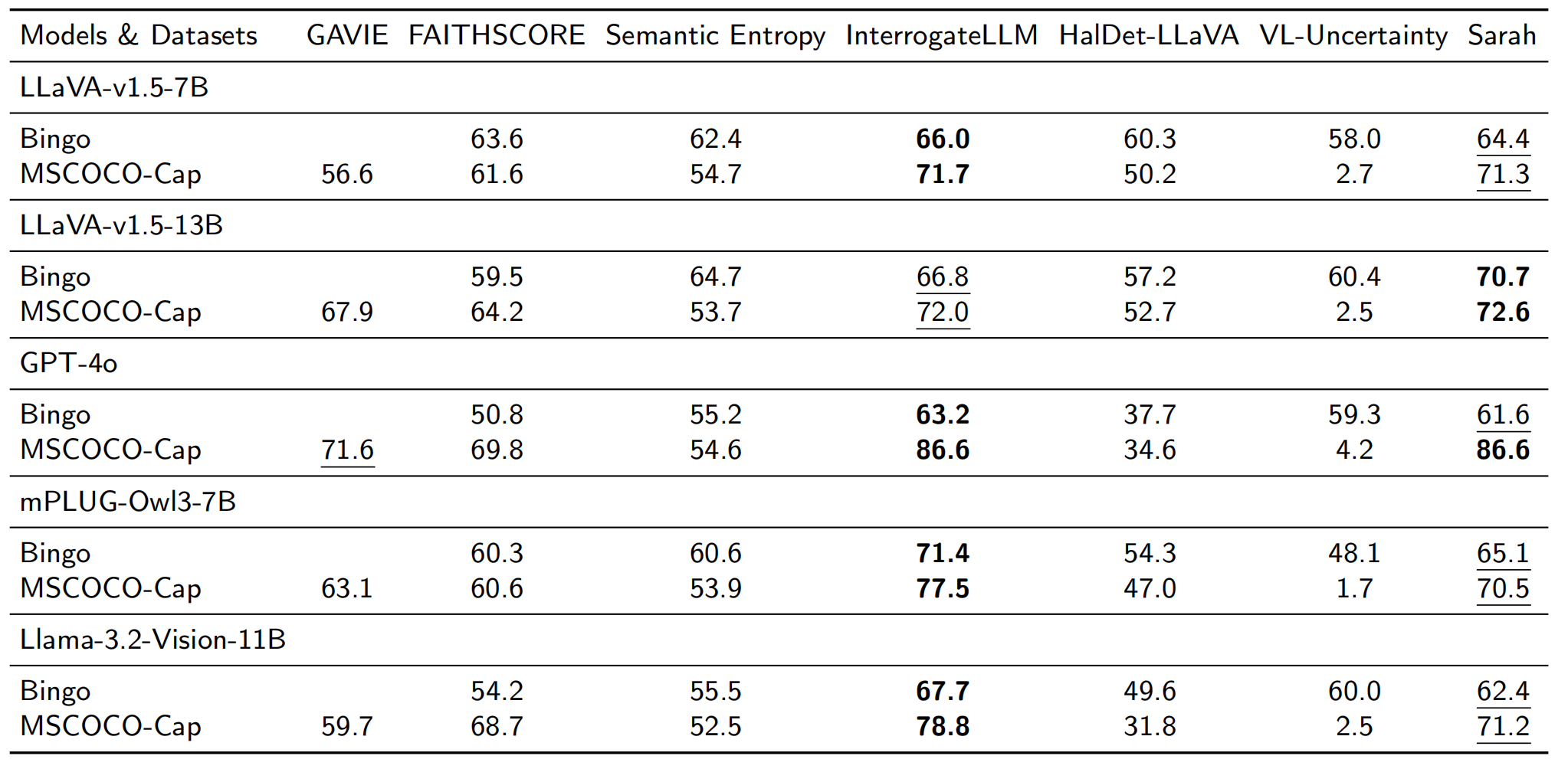
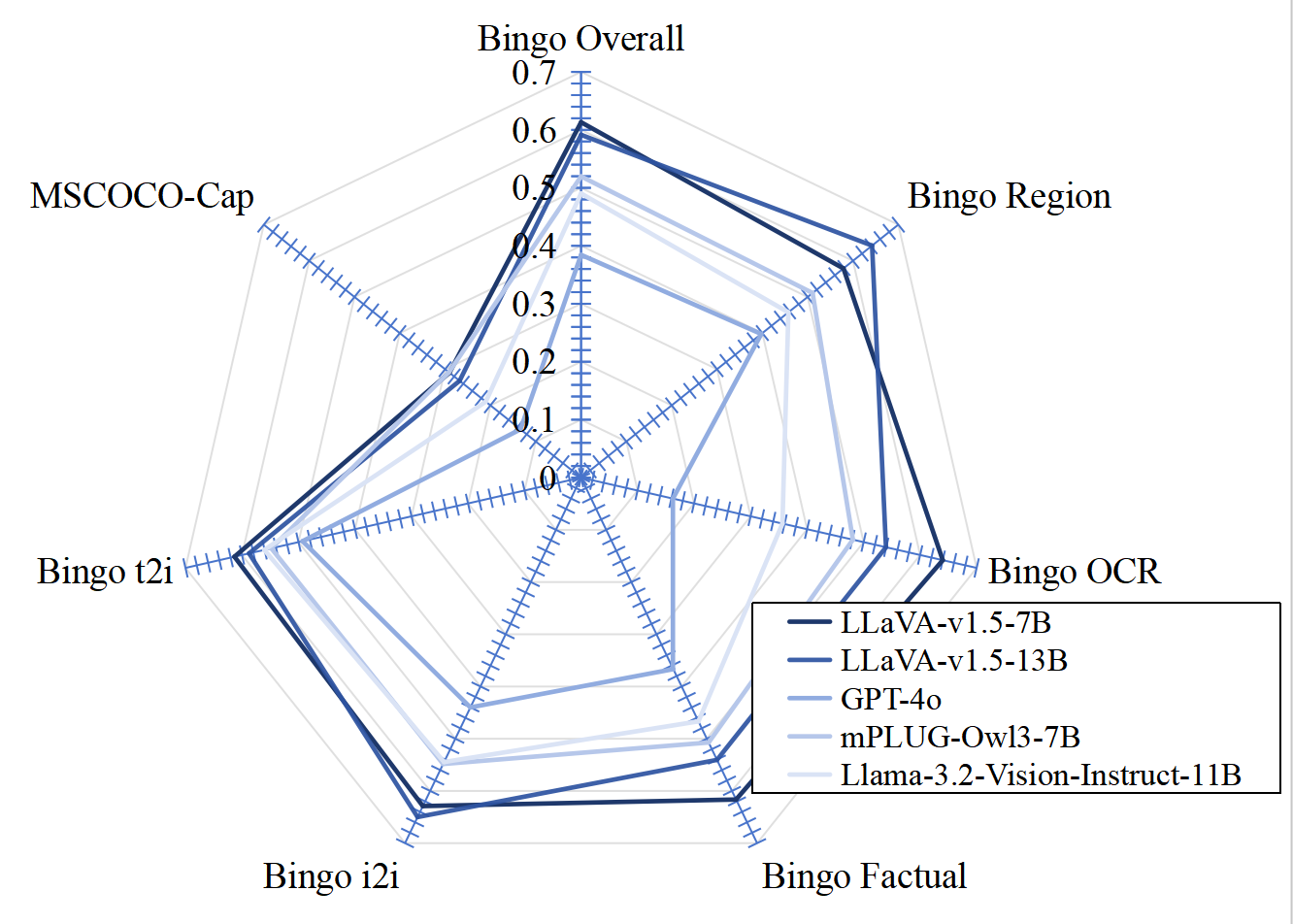
Sarah (Hallucination Detection for Large Vision Language Models with Semantic Information Locator and Purifier in Uncertainty Quantification Method) is a novel hallucination detection framework grounded in uncertainty quantification method. Video. Sarah Running on the Web Different from most existing uncertainty-based methods that utilize the variance of multi-round inference and need complex external tools, Sarah requires only single-round of inference result and minimal dependence on external tools, delving deeply into the value of the probability distribution. Considering uneven distribution of semantic information in both complete generation as well as possible outputs per-step, Semantic Information Locator and Purifier are proposed to enhance semantic collaboration and reduce semantic interference. Fig1. Overview of the Sarah framework for hallucination detection in LVLMs. Our extensive experiments across 5 off-the-shelf LVLMs and 2 open-ended visual question-answering benchmarks demonstrate that Sarah demonstrates superior performance by outperforming five out of six selected strong baseline methods in hallucination detection, achieving comparable detection accuracy.Specifically, on image captioning outputs generated by GPT-4o, Sarah achieves a hallucination detection accuracy of 86.6%. Fig.2 Comparison with state-of-the-arts on free-form benchmark (MSCOCO-Cap and Bingo) for LVLMs hallucination detection. It has also significantly enhanced cost-effectiveness (requires only 1/25 of the computational time per iteration). Fig3. Resource consumption across diverse hallucination detection methods. This analysis evaluates whether a detection method requires (1) multi-round reasoning and (2) image inputs, both of which significantly affect GPU memory requirements. The actual iteration time for each method is also provided in the table. Analysis over LVLMs further exposes critical limitations: over 13.4% of outputs from state-of-the-art LVLMs exhibit hallucination, which leaves room for future improvements. Fig4. Hallucination rate of different LVLMs based on Sarah.